Lời dẫn: Chia tách từ là vấn đề của tiếng Việt, tiếng Trung và một số tiếng khác. Một câu viết thông thường trong tiếng Việt là một chuỗi các tiếng (cũng gọi là các chữ hay các âm tiết). Ta phải chia các tiếng thành các đoạn nhỏ hơn sao cho mỗi đoạn là một từ (đơn vị nhỏ nhất có nghĩa). Nói cách khác, ta gộp các tiếng cạnh nhau lại để trở thành từ đúng như ý ta hiểu. Vấn đề được gọi trong tiếng Anh là word segmentation. Dưới đây là bài báo (viết bằng tiếng Anh) liên quan đến vấn đề từ trong tiếng Việt. Nội dung của bài viết sẽ được bổ sung giải thích và chuyển dần sang tiếng Việt. Hệ thống chạy thực tế sẽ được triển khai sớm.
EMPIRICAL STUDY ON VIETNAMESE WORD SEGMENTATION
1. SUMMARY
In this paper, we investigate the problem of word segmentation for Vietnamese. Unlike other languages such as English, French where words are separated by space, in Vietnamese writing system, there is no special token to mark word boundary. Vietnamese words contain one or more syllables and spaces are used to separate syllables. The goal of word segmentation is therefore to consider whether to merge consecutive syllables into a single word. We show that by using Conditional Random Field along with some simple post-processing methods, good performance with F-measure of about 98% can be achieved. These results show this word segmentation system for Vietnamese is good enough to be used in real applications.
Keywords: Vietnamese Word Segmentation, Conditional Random Field, post-processing
2. INTRODUCTION
In Vietnamese text, words are difficult to be distinguished as there are only boundaries marked by space between syllables. Each Vietnamese word is constituted of one or multiple syllables. This phenomenon is the same for Mandarin while it is not the case for many languages, especially popular European languages: English, French. Moreover, about 85% of Vietnamese words are multiple syllables, about 80% of these syllables can stand alone form words. Therefore, a word segmentation task, i.e., how to combine syllables into words, is a crucial preprocessing step for Vietnamese Natural Language Processing. Note that, this task is to consider only how to form words from syllables, not how to divide complex words into sub-parts as with other languages: Arabic, German...
To better figure out this problem, let take one example. Supposing that we have one sentence as follows:
học sinh học sinh học .
As 'học' (learn), 'sinh' (give birth, produce), 'học_sinh' (pupil) and 'sinh_học' (biology) are all valid words in Vietnamese, ignoring the meanings, there are many ways to segment this sentence, for example:
học | sinh | học | sinh | học .
học_sinh | học | sinh | học .
học_sinh | học | sinh_học .
Here, for the ease of reading, we use '_' to separate syllables within a word and '|' as a word boundary. For this example, the only valid way is in bold. This example shows that for this task, in order to remedy the ambiguity issues, we should take into consideration the syntactic and semantic information. Though, in fact, for this example, the use of statistical models, such as language models could be enough. Even with human, there exist ambiguities. Until now, there are rules defined for Vietnamese word segmentation. They are useful but some of them are not yet proved to be helpful in application, e.g., one rule is to combine a first name and a last name to form a single word but is it good for Machine Translation?
Maximum Matching (MM) is considered as a standard algorithm for the word segmentation task. For Vietnamese Word Segmentation, it was first studied in [1]. At each position, this algorithm chooses a segmentation by determining the longest syllable sequence which forms a word. Though simple, this method works well in practice because longer words are more likely to be correct than short words. According to [1], the MM algorithm was augmented by using bigram statistics to resolve overlap ambiguities but the F-measure improvement is only of about 0.2 to 0.3%. PVnSeg is another Vietnamese Word Segmentation tool, which also try to augments MM by following the rule-based approach to detect compound formulas such as proper nouns, common abbreviations, dates, numbers, e-mail addresses... In [2], it is shown to achieved the best performance. However the reason is not clear as basically, this approach helps the system to better deal with unknown syllables. It is supposed to have a very small portion of unknown syllables in text. Moreover, most of the time, it's enough to consider each of them as a word and MM already do this implicitly.
Another approach is to recast the problem as a classification one as in [3]. Then, it is straightforward to use classification models such as Conditional Random Fields (CRFs) or Support Vector Machines (SVMs). In this article, this approach with CRF and SVM is shown to outperform MM to a large extent. However, in [2], this seems not to be the case on larger data as the difference between this approach and MM is rather small and even PVnSeg, the augmented version of MM, is shown to be better.
Regarding mixed results in the literature, the main goal of this article is to revise this problem in order to, hopefully, have more consistent results by using a larger and better data recently available. The performance of MM, CRF with some simple post-processing methods are compared and analyzed together.
The remaining part of this article is structured as follows. In Section 3, two methods are described in detail. Experimental results will be shown in Section 4. Finally, this article is finished with some conclusions in Section 5.
3. METHODS
In this section, two methods for word segmentations are presented. The former is Maximum Matching, the simple one, but its performance is not necessarily worst. For the later, this task is first considered as a classification problem, then Conditional Random Field is applied with handcrafted extracted features.
3.1. MAXIMUM MATCHING
Maximum Matching (MM) is a greedy method. At each position, longest words are selected where the length of a word is defined as its number of syllables. After that, we move to the next position just after the new word and do it again. If we meet any unknown syllable in the dictionary, we consider this as one word and continue. So come back to the previous example, for a sentence:
học sinh học sinh học .
The result should be:
học_sinh | học_sinh | học .
It makes a good choice for the first word but for the next two words, it makes a mistake 'học_sinh | học' should be 'học | sinh_học' instead.
3.2. CLASSIFICATION WITH CONDITIONAL RANDOM FIELD
First, the problem is recasted to a classification problem. In [3], there are three possible labels for each syllable: 'BW', 'IW', 'O'. 'BW' is for begin of word, 'IW' is for internal part of word and 'O' is for outside of word (for special token such as punctuation). The use of an additional label 'O' is not clear as the results of word segmentation are the same if we consider all 'O' as 'B_W'. Moreover, this mapping reduces the number of classes from 3 to 2, making the problem simpler. The results from preliminary experiments show that the performance is slightly better when using only 2 classes, so in the experimental part, we will only use CRF of 2 classes.
According to [3], the label for the correct segmentation of the example, 'học_sinh | học | sinh_học .', is shown in Table 1. Note that in the last line, for dot '.' we will substitute its label from 'O' to 'B_W'.
Table 1: Examples for class labels used in Word Segmentation
| Syllable | Label |
| học | B_W |
| sinh | I_W |
| học | B_W |
| sinh | B_W |
| học | I_W |
| . | O |
Now, the goal is to assign to each syllable a good label. To do that, we can use any classification method, here, we choose Conditional Random Field (CRF) because of its capacity of using rich and redundant features.
CRF we used is in fact linear-chain CRF, one type of an indirect graphical model, aiming at assigning labels to all elements in a sequence at the same time. To formulate the problem, first considering
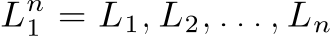 as a sequence of random variables used to represent labels (n is in general different for each sequence) and
as a sequence of random variables used to represent labels (n is in general different for each sequence) and
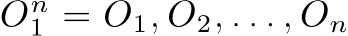 as a sequence of random variables representing observations (attributes), then, the task is to find the most likely sequence of labels for an observation sequence , i.e, finding the one that maximizes:
as a sequence of random variables representing observations (attributes), then, the task is to find the most likely sequence of labels for an observation sequence , i.e, finding the one that maximizes:
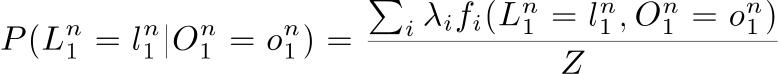
Z is a normalization factor, which is computed as:
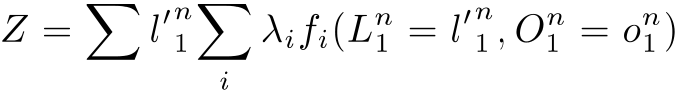
means summation over all possible values of labels.
Functions f are called feature functions. Each one is a Kronecker (δ) test function which fires when a set of attribute and label values satisfy some criteria. For example, if we define
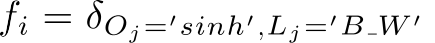 , it means that it fires when the jth word is 'sinh' and the label for this word is 'B_W'.
, it means that it fires when the jth word is 'sinh' and the label for this word is 'B_W'.
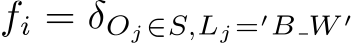 means that it fires when the jth word is in a set and the label for this word is 'B_W'. We can also test if the value of is in a specification format (time, date, number...)
means that it fires when the jth word is in a set and the label for this word is 'B_W'. We can also test if the value of is in a specification format (time, date, number...)
In general, feature functions could be defined arbitrarily but for a linear-chain CRF, only combinations of attributes and one label and combinations of two consecutive labels are accepted. It means that this type of model cannot capture dependencies between labels other than two consecutive ones (label bigrams). The features which are conditioned on combinations of attributes and one label are called state features whereas the features which are conditioned on label bigrams are called transition features. For instance,
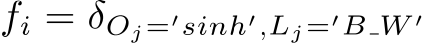 is a state feature whereas
is a state feature whereas
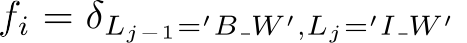 is a transition feature.
is a transition feature.
Set of is parameters to be learned. These optimal values could be found by maximizing likelihood for all sequences on the training data :
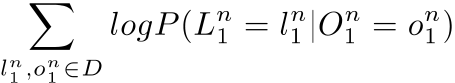
It should be noted that the summation above is convex, so the global optimum can be found, by carrying out certain numerical optimization algorithms, such as Stochastic Gradient Descent or Gradient Descent using the L-BFGS. To prevent overfitting, L2 regularization term should be used.
The performance of this type of model strongly depends on the choice of feature functions. As CRF is often known to be robust with redundant features, one naive solution is to add as many types of features as possible. However, in practice, for the computational cost reason, eliminating useless features is necessary.
For word segmentation, similar to [3], we consider a set of features presented in Table 2. Detailed descriptions for these features will be shown in Section 4.
3.3. ADDITIONAL RESOURCES
As shown in [3], there are additional resources which could also be helpful. They are provided along with the toolkit JVnTextPro (http://jvntextpro.sourceforge.net/) of [3]. The first one is the dictionary, which contains 70,592 words. Many are multiple syllable words which do not occur in the word segmentation corpus. The second one is the list of locations taken from Wikipedia. The third one is the list of proper names. Both last two resources could be used to deal with the name entity.
For MM, all three additional resources are taken following the same way. All are considered as words and are added to extend the dictionary.
For CRF, the additional features are defined which fire whether words are in the dictionary ('dict'), in the list of locations ('locations') or in the list of first names ('first_names'), middle names ('middle_names'), last names ('last_names') extracted from a list of proper names.
3.4. POST-PROCESSING
There are two post-processing methods inspired from two simple observations. The first one is that the unknown syllables are often grouped in one word, so we scan the output text from a word segmentation model and group all consecutive unknown words if each of them is a single one, i.e., containing only 1 syllable. We use 'unk' to denote this post-processing method.
The second observation is that, the most frequent ambiguity is between two possible segmentation solution for 3 syllables ('a b c'): considering them as 2-syllable word ('a_b'), then 1-syllable word ('c') or vice-versa, 1-syllable word ('a') then 2-syllable word ('b_c'). For example, 'học_sinh | học' or 'học | sinh_học' for 'học sinh học'. We call it 'overlap ambiguity'. Most of the time, this issue can be resolved by using information from statistics drawn from the training data. Here we simply use probabilities based on unigram, so the choice depends on the comparison between P('a') + P('b_c') and P('a_b') + P('c'). This probability is computed from the word frequency counted in the training data. Using probabilities with higher order of gram is possible but we leave this investigation as a future work. We call this method 'uni'.
4. EXPERIMENTAL RESULT
The text used was induced from the corpus of KC01/06-10 project "Building Basic Resources and Tools for Vietnamese Language and Speech Processing" (VLSP). The corpus for word segmentation consisted of 62,873 sentences, of 1,537,068 running words. We divided it into 5 chunks and then carried out 5-fold Cross Validation: for each setup, we took 4 parts as the training data and the rest as the test data. The experimental results reported in Table 3 are the average on 5 setups.
To evaluate a model, we used F-measure which is computed from Precision and Recall. Concretely, supposing that there are Nref words in a reference, Nhyp words in the output of a model and Ncor words which are correctly segmented, Precision and Recall are computed as follows:
Precision = Ncor / Nhyp
Recall = Ncor / Nref
Then, we obtain F-measure as the average of Precision and Recall.
F-measure = (Precision + Recall) / 2
CRFs were trained using CRFsuite [4]. There are only 2 types of labels (B_W, I_W) instead of 3 (B_W, I_W, O) compared with [3] as preliminary experimental results show that the former configuration is better. Scripts for all experiments were roughly based on the code provided by Anindya Roy (https://github.com/roy-a/Roy_VnTokenizer).
List of state features for CRF are summarized in Table 2. The transition features are also used but their parameters are learned from the statistics on the training data for bi-gram labels. They are fixed, the Gradient Descent with L-BFGS algorithm modifies only parameters of state features.
The first three lines are for the n-gram features.
The next eight lines are for the features testing whether a word formed by n-gram is in the 'dict', 'first_name', sets obtained from the additional resources...
The remaining lines are for the features testing word format.
Table 2: Features for CRF
| Feature | Position |
| unigram | (-2), (-1), (0), (1), (2) |
| bigram | (-2, -1), (-1, 0), (0, 1), (1, 2) |
| trigram | (-2, -1, 0), (-1, 0, 1), (0, 1, 2) |
| unigram in 'dict' | (-2), (-1), (0), (1), (2) |
| bigram in 'dict' | (-2, -1), (-1, 0), (0, 1), (1, 2) |
| trigram in 'dict' | (-2, -1, 0), (-1, 0, 1), (0, 1, 2) |
| unigram in 'first_name' | (-2), (-1), (0), (1), (2) |
| unigram in 'middle_name' | (-2), (-1), (0), (1), (2) |
| unigram in 'last_name' | (-2), (-1), (0), (1), (2) |
| bigram in 'location' | (-2, -1), (-1, 0), (0, 1), (1, 2) |
| trigram in 'location' | (-2, -1, 0), (-1, 0, 1), (0, 1, 2) |
| is numbers, percentages or money | 0 |
| is short and long dates | 0 |
| has initial capital | 0 |
| has all capitals | 0 |
| is punctuation or special characters | 0 |
All results are grouped in Table 3. In this table, '+lex' stands for the use of three additional resources (dictionary, list of locations and list of proper names). '+lexwot' is '+lex' but eliminating words that have more than 2 syllables and 2-sylllable words which are separated at least once in the training data. '+unk' stands for the 'unk' post-processing method. '+uni stands for the 'uni' post-processing method.
In all configurations, CRF is better than MM. In the best configuration, CRF outperforms MM of about 1.1% (97.80% compared with 96.68%).
Using additional resources is only helpful for CRF (see line 2 and 3 of the table). For MM, the result drops down significantly with '+lex' but remains almost the same with '+lewwot'. So for MM, it is even harmful if we don't resolve the inconsistency between multiple syllable words induced from 'dict' and the training data. On the contrary, the performance of CRF is better in the two cases, showing that CRF is more robust in combining features.
Two post-processing steps are helpful but the improvement is not at the same order between MM and CRF. While '+unk' always helps, the use of unigram to resolve the ambiguity brings a significant improvement only for MM. The average number of edition after doing unigram post-processing is 190 for MM and 5 for CRF. This fact implies that by taking n-gram features, CRF can well handle this overlap ambiguity.
We take a quick glance at the output of the best system and find that many errors are hard to correct because they are caused by the inconsistency existing in the training data. A large part of the other errors could be corrected by applying some simple post-processing rules.
Table 3: Word Segmentation with F-measure (in %).
| Method | MM | CRF |
| 96.36 | 96.76 | |
| +lex | 89.14 | 97.63 |
| +lexwot | 96.36 | 97.74 |
| +lexwot+unk | 96.48 | 97.80 |
| +lexwot+unk+uni | 96.68 | 97.80 |
- CONCLUSION
In this article, by comparing and analyzing two methods, named Maximum Matching and Conditional Random Fields, for Vietnamese Word Segmentation, we show that CRF is better. The result of about 98% seems to be good enough to be used in real applications. CRF is shown to be robust in combining different types of features and is good at resolving the overlap ambiguity issue. The use of statistical language models for post-processing seems not to be very helpful for CRF. Future work should focus on analyzing the errors of CRF and on finding some post-processing rules to correct them.
REFERENCES
[1] H. P. Le, T. M. H. Nguyen, A. Roussanaly, and T. V. Ho. (2008). A hybrid approach to word segmentation of Vietnamese texts. In 2nd International Conference on Language and Automata Theory and Applications, Tarragona, Spain.
[2] Q. T. Dinh, H. P. Le, T. M. H. Nguyen, C. T. Nguyen, M. Rossignol, and X. L. Vu. (2008). Word segmentation of Vietnamese texts: a comparison of approaches. LREC 2008.
[3] C. T. Nguyen, T. K. Nguyen, X. H. Phan, L. M. Nguyen, and Q. T. Ha. (2006). Vietnamese word segmentation with CRFs and SVMs: An investigation. In Proceedings of the 20th Pacific Asia Conference on Language, Information and Computation (PACLIC 2006)
[4] Naoaki Okazaki. (2007). CRFsuite: a fast implementation of Conditional Random Fields (CRFs). http://www.chokkan.org/software/crfsuite/