“Tiếng vĩ cầm réo rắt, tiếng dương cầm du dương”
Hồi trẻ, thầy vật lý dạy sự khác biệt là do âm sắc. Sự khác biệt có thể thấy rõ khi nhìn tín hiệu trong miền tần số. Hình ảnh trong miền tần số đó gọi là phổ tín hiệu.
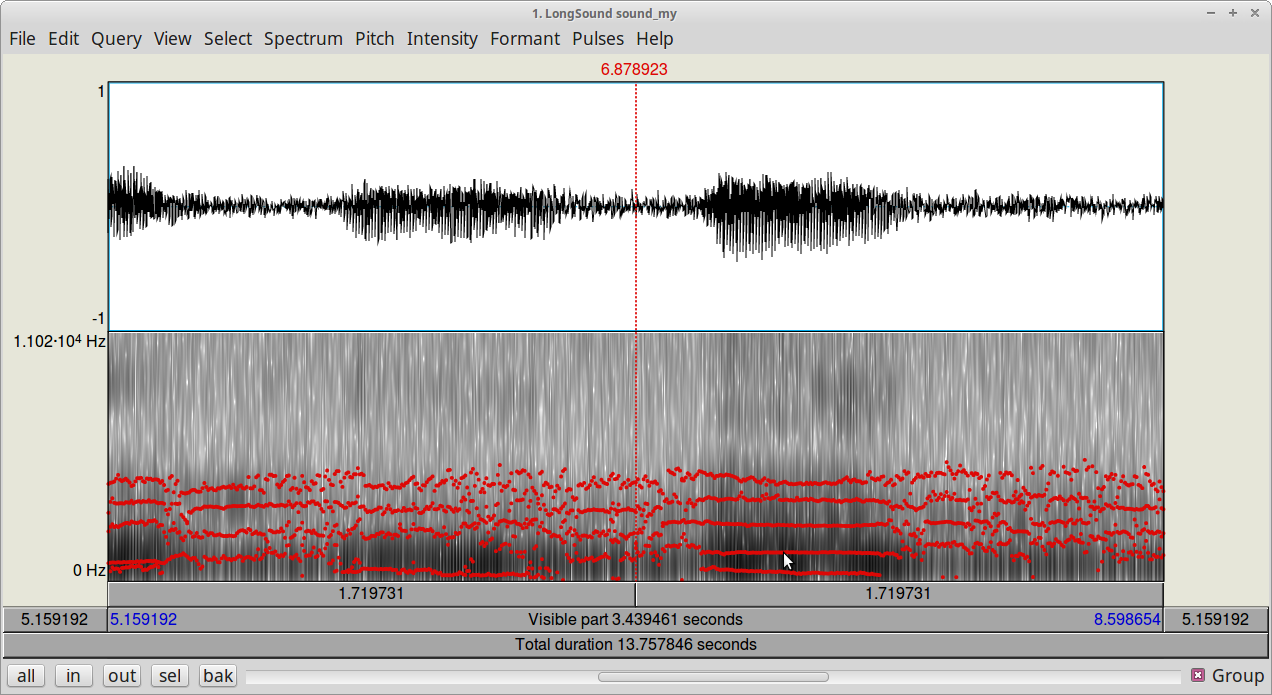
Biểu đồ 2.6: Formant với Praat [1]
Ví dụ về nhạc cụ chỉ mang tính chất gợi mở, ke ke. Tôi sẽ tập trung vào tiếng nói. Phổ tín hiệu có thể được thể hiện ở phần phía dưới trong hình vẽ 2.6. Trục ngang là thời gian. Trục dọc là tần số (từ 0 đến 11025Hz). Trọng lượng của tần số hình thành nên tín hiệu được thể hiện trong dải màu đen trắng: Từ trắng đến đen nghĩa là từ thấp đến cao. Ở miền thời gian phía trên có hai phần. Các cục to là khi tôi nói một nguyên âm, tương ứng với phần phía dưới là các vùng khu tần số thấp đen đậm hơn. Chỗ đều đều là tín hiệu âm thanh môi trường có nhiễu, các tần số có trọng lượng thấp mờ nhạt hơn.
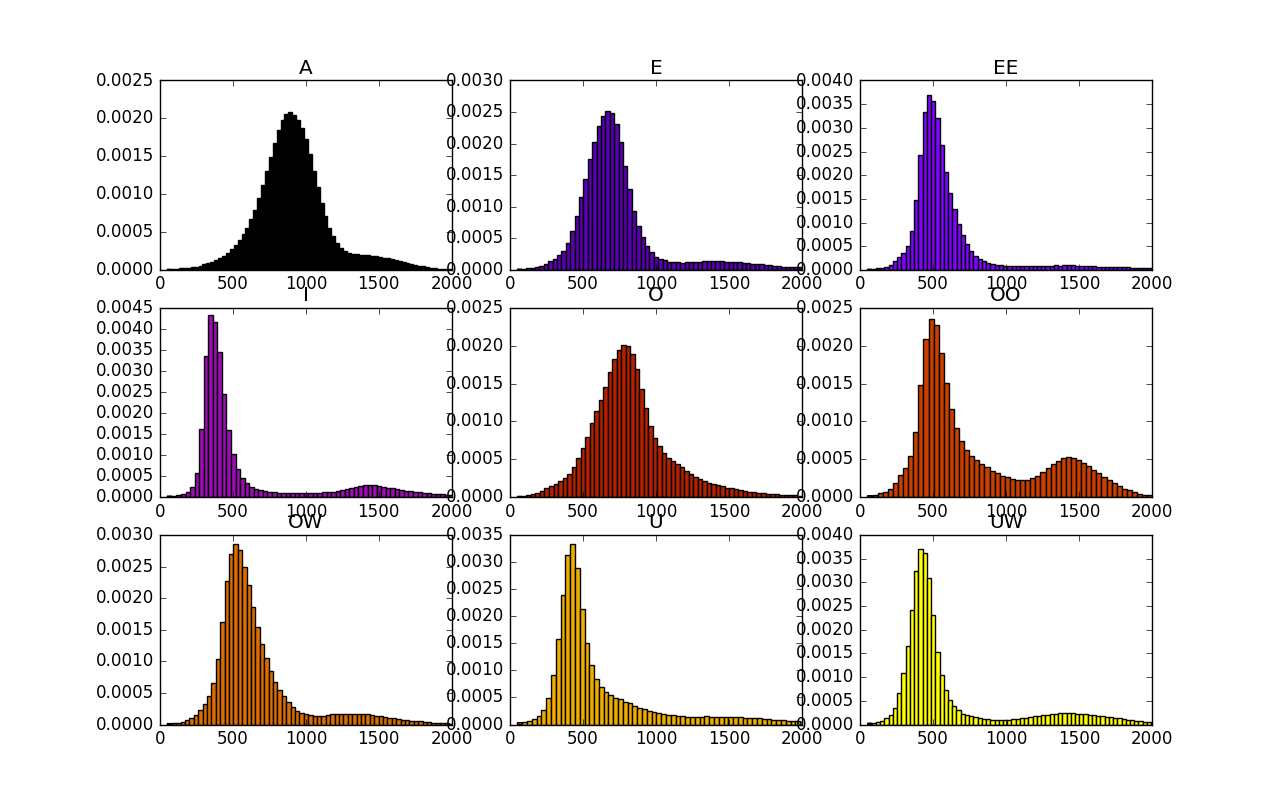
Biểu đồ 2.7: Phân bố f1 của nguyên âm đơn tiếng Việt
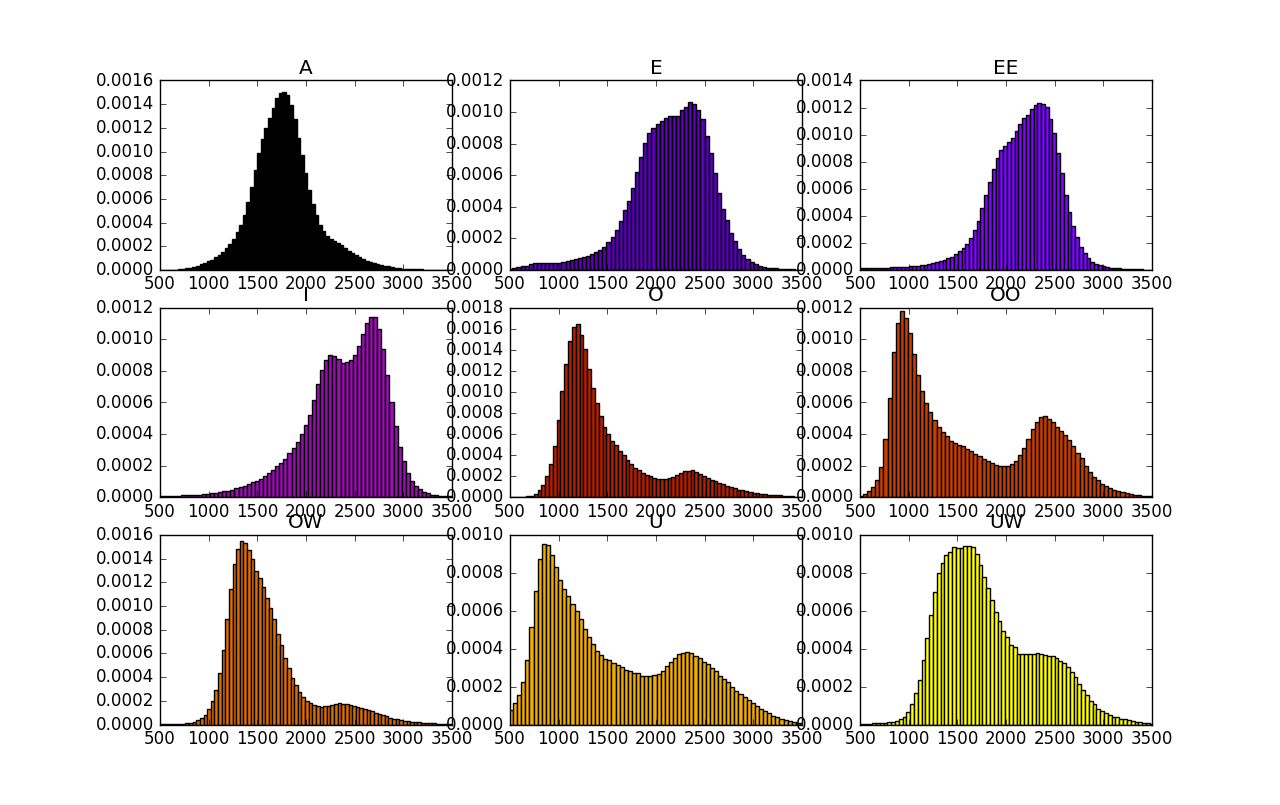
Biểu đồ 2.8: Phân bố f2 của nguyên âm đơn tiếng Việt
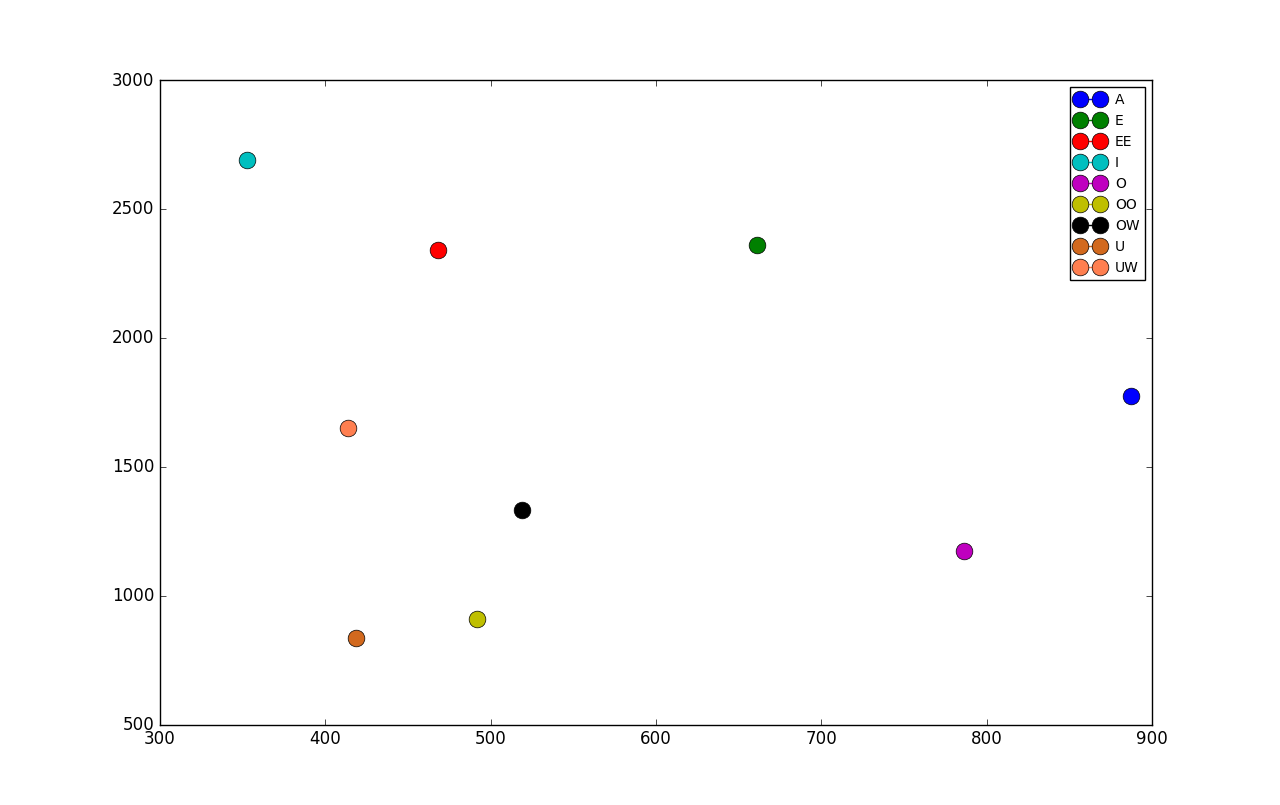
Biểu đồ 2.9: Bản đồ formant (f1, f2) của nguyên âm đơn tiếng Việt
Ở phần các cục to to là các tiếng nói hữu thanh, ta thấy có các dải đỏ chạy khá ổn định. Đó là các điểm thể hiện formant. Formant đơn giản là các điểm cực đại cục bộ của phổ, nghĩa là các tần số có trọng lượng cao hơn so với các tần số nằm xung quanh. Tất nhiên xung quanh phải đủ rộng thì mới có ý nghĩa. Các formant không thể hiện hết phổ nhưng đóng vai trò đại diện khá ổn. Ta có âm sắc (phổ) các formant.
Ta có thể phân biệt các nguyên âm bằng phổ của chúng, nghĩa là có thể ở mức độ nào đó sử dụng formant để phân biệt. Ở ba hình vẽ 2.7, 2.8, 2.9 là các formant của nguyên âm tiếng Việt được thống kê từ bộ dữ liệu thu âm các câu nói của một số người Việt. Dữ liệu gồm 168 nữ, 38 nam, 102712 câu nói. Dữ liệu câu nói được gán nhãn ở mức câu, nghĩa là tương ứng với mỗi file wav câu nói đó sẽ có một dòng văn bản đi kèm thể hiện là người đó đã nói gì. Sau đó tôi sử dụng công cụ Kaldi [3] để xây dựng hệ thống Ghi lại lời nói, từ đó gán nhãn tự động các câu ở mức âm vị (phoneme). Âm vị là đơn vị nhỏ hơn tiếng, ví dụ như từ /bán/ có thể phân tách thành ba âm vị /B/, /A/, /NC/. Từ đó ta có tương ứng với mỗi đoạn tín hiệu (đoạn file wav) là loại âm vị gì (hoặc không xuất hiện tiếng nói, coi như âm vị đặc biệt /SIL/ (silence - khoảng lặng). Có thống kê âm vị (bỏ qua SIL) xuất hiện trong cơ sở dữ liệu như trong Biểu đồ 2.10. Chú ý là các âm vị không được kí hiệu như theo IPA mà là theo kiểu Telex. Do đó OW là Ơ, UW là Ư, UWOW là nguyên âm đôi ƯƠ, OO là Ô, EE là Ê... Ngoài ra âm vị có C ở cuối là để chỉ âm vị nằm ở vị trí cuối. Ví dụ N là âm vị nằm ở đầu, trong /năm/, /no/..., còn NC là âm vị nằm ở cuối, trong /tan/, /bốn/. Đây là một cách phân loại âm vị tôi cảm thấy phù hợp cho việc phát triển hệ thống Ghi lại lời nói. Có nhiều cách phân loại âm vị. Chi tiết về chúng xin hẹn bạn đọc trình bày vào một dịp khác.
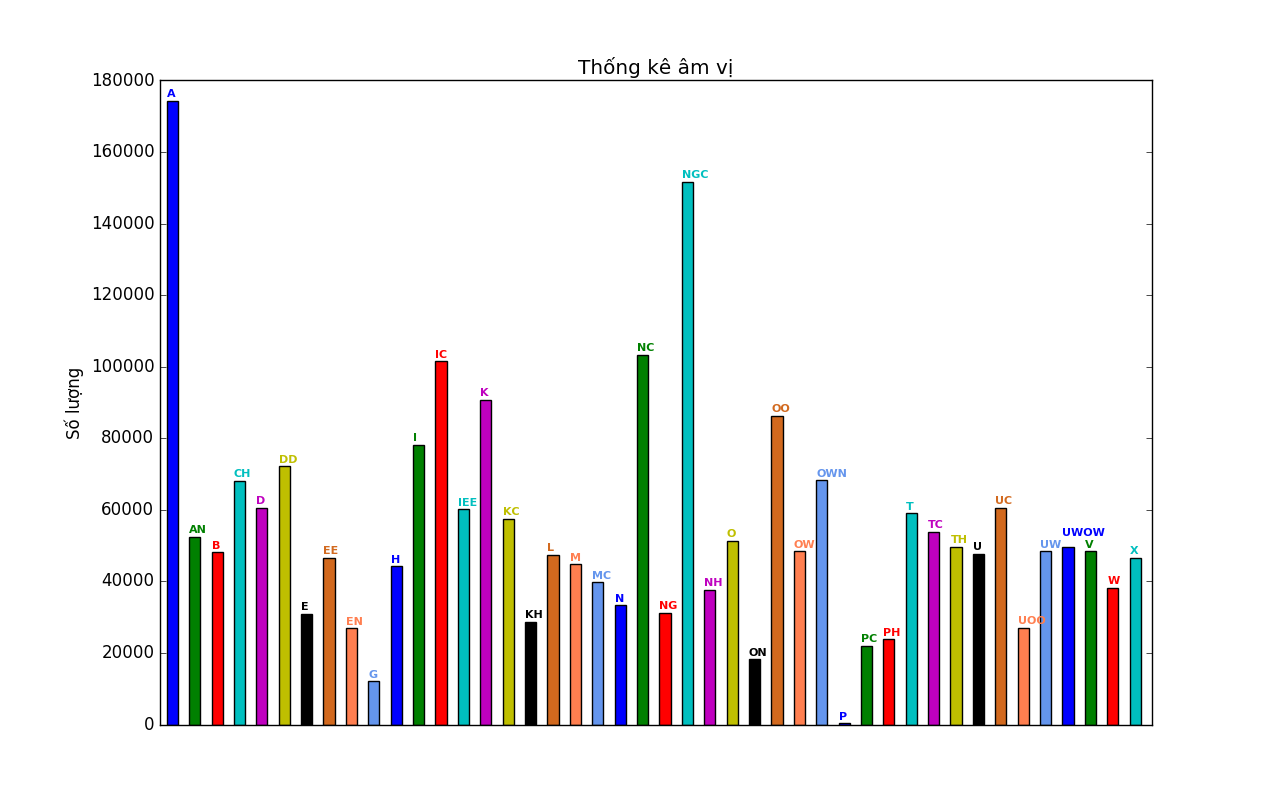
Biểu đồ 2.10: Thống kê âm vị trong cơ sở dữ liệu
Cuối cùng tôi sử dụng Praat [1] để tính toán formant cho từng đoạn, rồi vẽ biểu đồ tần suất (histogram). Đỉnh của histogram cho từng nguyên âm được cho vào trong bảng 2.1.
Bảng 2.1: Giá trị formant thường gặp của nguyên âm
| Nguyên âm | f1 | f2 |
| A | 887 | 1774 |
| E | 661 | 2359 |
| EE (Ê) | 468 | 2341 |
| I | 352 | 2692 |
| O | 786 | 1172 |
| OO (Ô) | 491 | 907 |
| OW (Ơ) | 518 | 1331 |
| U | 418 | 834 |
| UW (Ư) | 413 | 1651 |
Có thể thấy rằng kết quả rất phù hợp với các kết luận đã có từ trước. Ví dụ như trong ngôn ngữ học, ngữ “chưa mua mía” có các nguyên âm đôi /uw-ow/, /u-oo/, /i-ee/ được cho là biến đổi từ nguyên âm đơn bắt đầu (/uw/, /u/, /i/) sang nguyên âm kết thúc (/ow/, /oo/, /ee/) hướng về phía nguyên âm /a/. Do đó mới bị viết lệch thành “a” ở cuối. Ta có thể vẽ đường di chuyển rất đẹp của chúng (màu đỏ) trên hình vẽ 2.9.